
Contexto
El cliente tiene un “centro de servicios compartidos” el cual es un área de apoyo operativo encargada de prestar diferentes servicios relacionados con gestión documental para todas las áreas del negocio. Resulta fundamental realizar una apropiada planeación de la capacidad de esta área para poder garantizar la prestación de los diferentes servicios dentro de los tiempos y acuerdos de niveles de servicio establecidos.
Esta planeación parte de entender el comportamiento de la demanda en el pasado para predecir la demanda futura y poder así planear la capacidad que se deberá garantizar.
Descripción del problema
De los 14 modelos existentes para predecir las variables asociadas a la demanda de servicios del “centro de servicios compartidos”, se contaba con código en R que desarrollaba modelos de tipo (S)ARIMA. Sin embargo, diversos modelos no estaban arrojando resultados o métricas de evaluación aceptables o confiables para el negocio, por lo cual se debían recalibrar y operacionalizar, con el objetivo mejorar su capacidad predictiva.
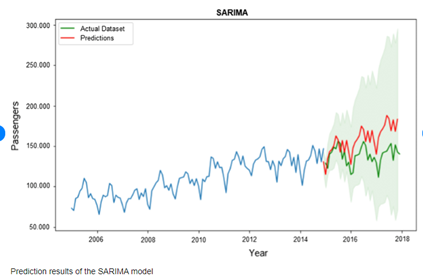
Descripción de la solución
Se desarrolló una solución que permite el reajuste de los modelos que ya habían sido desarrollados previamente, empleando el enfoque de Box y Jenkins, más exactamente conocidos como modelos SARIMA.
De los 14 modelos existentes, se implementó un enfoque de Machine Learning para 5 modelos, relacionados con los procesos de viajes, selección de personal, vivienda y aprendizaje interno. Este enfoque consistió en implementar un marco de trabajo conocido como “Modeltime”, en el cual se desarrollaron diversos algoritmos para mejorar los resultados de evaluación de cada uno de los modelos anteriormente mencionados. De esta manera, se crearon algoritmos como XGBoost, “bosques aleatorios” y Prophet para observar tanto de manera individual como conjunta el desempeño de los modelos.
Se utilizaron como métricas de evaluación el MAPE (Error porcentual absoluto medio) y RMSE (Raíz cuadrada del error cuadrático medio).Con esta metodología se evidenció una mejoría significativa en el desempeño de los modelos en cuestión.
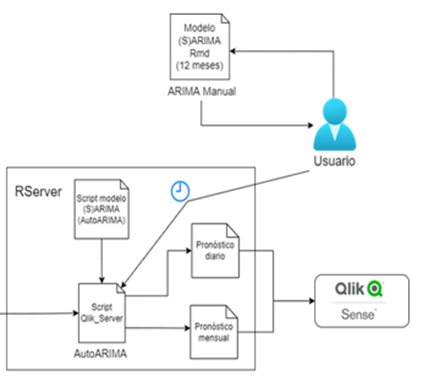
Actividades clave realizadas
- Realizar ingeniería de características al conjunto de datos a modelar con el fin de aumentar su capacidad predictiva.
- Implementar “recetas” para realizar una preparación de los datos para el modelado de una manera más cómoda mediante canalizaciones.
- Desarrollar flujos de trabajo para cada uno de los algoritmos de aprendizaje automático que se quieran implementar y adherirlos fácilmente a las “recetas”.
- Crear modelos conjuntos a partir de los algoritmos individuales ya implementados, es decir, unir los aportes de los algoritmos individuales en uno solo.
- Realizar gráficas descriptivas de valor para observar el pronóstico de todos los algoritmos implementados y analizar gráficamente cuál se ajusta mejor y cuál no se ajusta tan bien.
Beneficios para el negocio
Al mejorar significativa el desempeño de los modelos en cuestión se mejoró también la capacidad de predicción de la demanda y por tanto se pudo realizar una planeación más adecuada del personal requerido en el centro de servicios compartido, y reducir con esto costos operativos.
Tecnologías utilizadas
- Algoritmos de Machine Learning para series temporales univariadas en R.
- Lenguaje estadístico R
- Marco de trabajo “Modeltime”



