La Revolución de la Infraestructura de Datos: Fundamentos y Evolución
En el tejido de la economía digital contemporánea, la ingeniería de datos ha trascendido su función tradicional de soporte operativo para convertirse en la columna vertebral estratégica de la innovación empresarial. Ya no se trata simplemente de mover información de un punto A a un punto B; la ingeniería de datos moderna es la disciplina que rige el diseño, la construcción y el mantenimiento de sistemas complejos que transforman datos brutos —a menudo caóticos y no estructurados— en activos de conocimiento unificados, fiables y listos para el consumo analítico y algorítmico.
La evolución de esta disciplina ha sido vertiginosa. Hace apenas una década, el foco principal residía en la gestión de bases de datos relacionales y almacenes de datos estáticos. Sin embargo, la explosión del Big Data obligó a un cambio de paradigma radical. Hoy, nos encontramos en una era donde la infraestructura debe soportar no solo el análisis histórico, sino también la ingesta en tiempo real, el procesamiento de eventos complejos y la alimentación continua de modelos de inteligencia artificial generativa.
La ingeniería de datos actúa como el «arquitecto invisible» que habilita todas las capas superiores de valor. Sin tuberías de datos (pipelines) robustas, la ciencia de datos es incapaz de operar; los ingenieros preparan grandes conjuntos de datos para que los analistas y científicos puedan utilizarlos de manera efectiva. Por tanto, esta disciplina no es solo una función técnica, sino un habilitador crítico de eficiencia operativa y ventaja competitiva, permitiendo que las organizaciones hagan una transición de una postura reactiva a una proactiva impulsada por la información.
Diferenciación de Roles: El Ecosistema de Datos
Para comprender la magnitud de la ingeniería de datos, es esencial delimitar sus fronteras. Aunque complementarias, las funciones de ingeniero, científico y analista son profundamente distintas en naturaleza y objetivo.
- El Ingeniero de Datos: Es el constructor. Su enfoque está en la infraestructura, la escalabilidad y la fiabilidad. Se pregunta: «¿Cómo podemos capturar, procesar y entregar estos datos de forma eficiente y segura?». Es responsable de los procesos ETL/ELT y de garantizar que la arquitectura pueda resistir fallos. Sus competencias incluyen el dominio de Spark, Kafka, y plataformas como AWS, Azure y Databricks.
- El Científico de Datos: Es el explorador y matemático. Su materia prima son los datos que el ingeniero ha preparado. Utiliza estadística avanzada y algoritmos de Machine Learning para construir modelos predictivos. Su foco no es la eficiencia del pipeline, sino la precisión del modelo.
- El Analista de Datos: Actúa como el traductor que interpreta la información para responder preguntas de negocio inmediatas y comunicar hallazgos a los interesados.
| Característica | Ingeniero de Datos | Científico de Datos | Analista de Datos |
| Enfoque Principal | Infraestructura y Pipelines | Modelado Predictivo y ML | Inteligencia de Negocio (BI) |
| Pregunta Clave | ¿Cómo muevo y limpio el dato? | ¿Qué historias oculta el dato? | ¿Qué pasó y por qué? |
| Entregable | Tablas limpias, APIs, Data Lakes | Modelos, Algoritmos, Predicciones | Dashboards, Informes, KPIs |
| Herramientas | Kafka, Spark, AWS, Azure, Databricks | Python, R, TensorFlow, scikit-learn | Power BI, Tableau, SQL, Excel |
Esta distinción es vital: mientras un analista necesita interpretar datos, el ingeniero crea los programas y sistemas que permiten que esos datos existan en una disposición adecuada para el estudio. Sin un buen trabajo del ingeniero, los analistas y científicos estarían limitados o incluso bloqueados.
El Ciclo de Vida del Dato: Ingesta, Transformación y Servicio
La ingeniería de datos rige el viaje completo del dato a través de tres fases críticas que garantizan su calidad y disponibilidad.
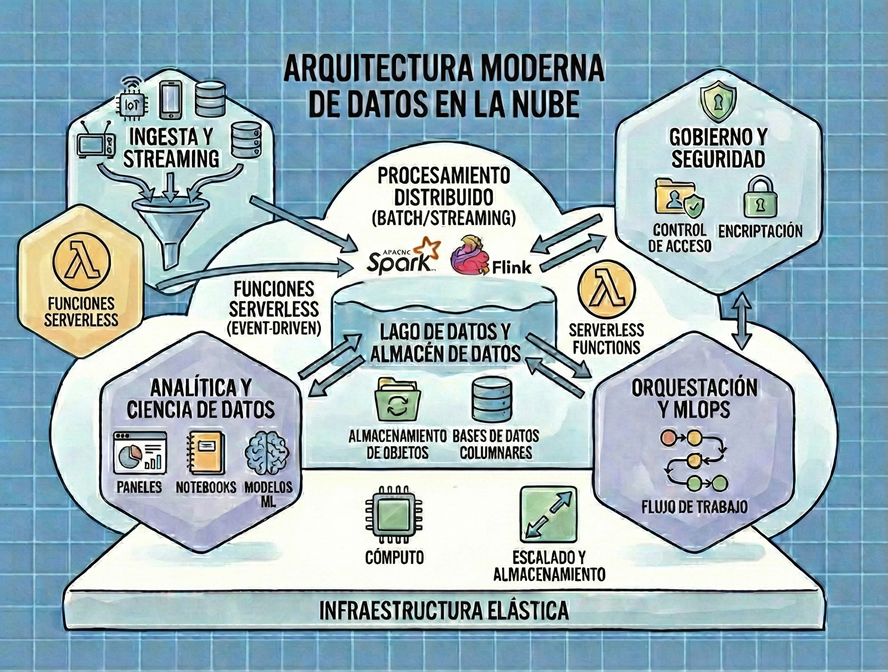
Ingesta de Datos: El Primer Kilómetro
La fase de ingesta es el movimiento de datos desde diversas fuentes —bases de datos, plataformas cloud, dispositivos IoT, sitios web— hacia un único ecosistema organizado.
- Procesamiento por Lotes (Batch): Es el método tradicional donde los datos se recolectan en intervalos definidos. Es ideal para grandes volúmenes de datos históricos.
- Procesamiento en Tiempo en Linea (Streaming): Fundamental para casos como detección de fraude y personalización inmediata. Aquí, herramientas como Amazon Kinesis, Azure Event Hubs y Apache Kafka permiten una ingesta continua con latencias de apenas segundos.
Transformación: Del Caos al Valor
La transformación prepara los datos para el usuario final. Es un ejercicio de «higiene» que corrige errores, elimina duplicados y normaliza la información para asegurar su fiabilidad. En arquitecturas modernas de nube, se prefiere el modelo ELT (Extract, Load, Transform), donde los datos se cargan primero en bruto y se transforman usando la potencia de cómputo del destino, como en un Delta Lake o un Data Warehouse cloud.
Servicio y Consumo
Finalmente, los datos se entregan al usuario a través de visualizaciones, informes automatizados o conjuntos de datos para entrenamiento de IA. El éxito en esta fase se mide por la «frescura» y la precisión de la información servida.
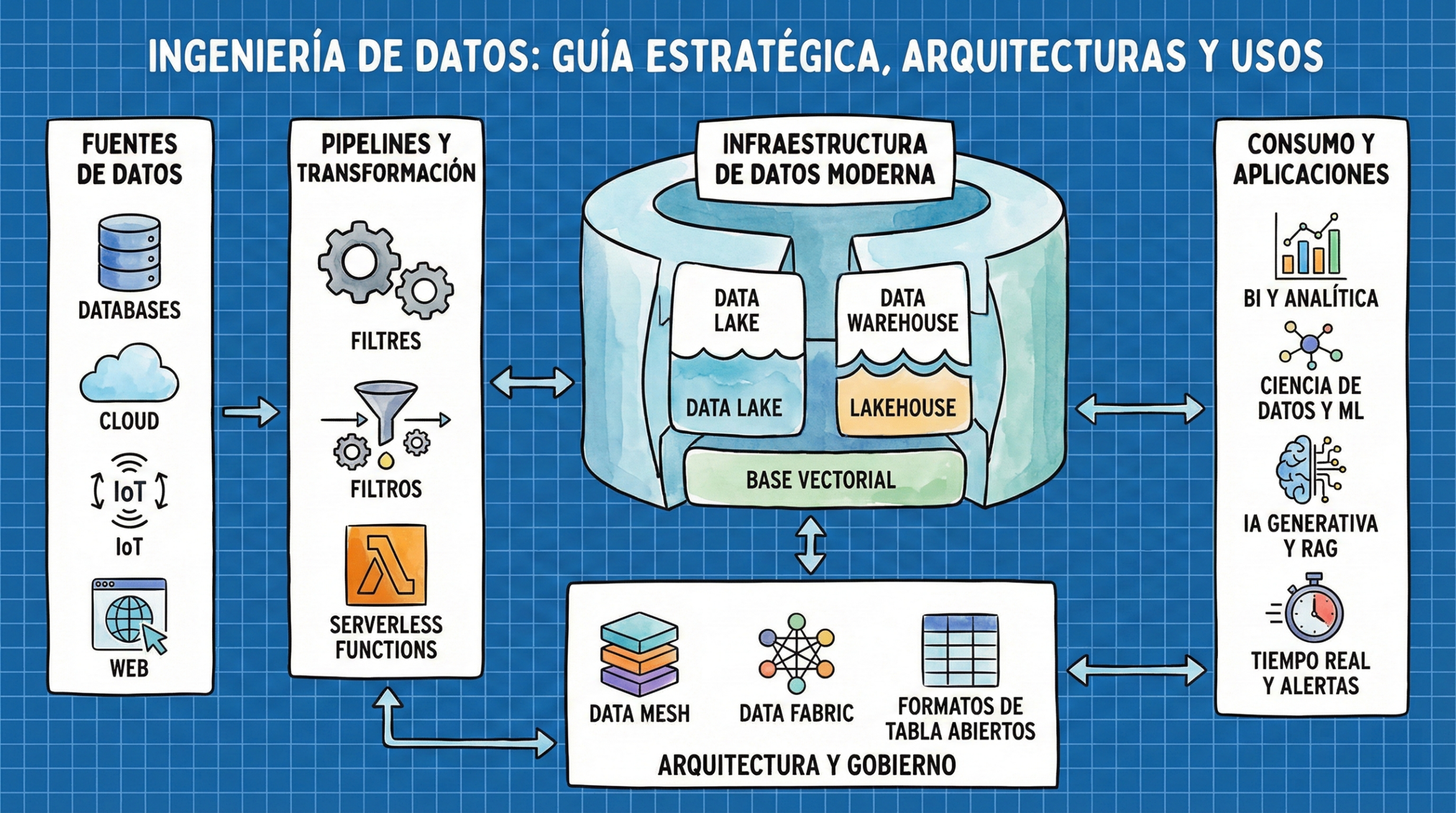
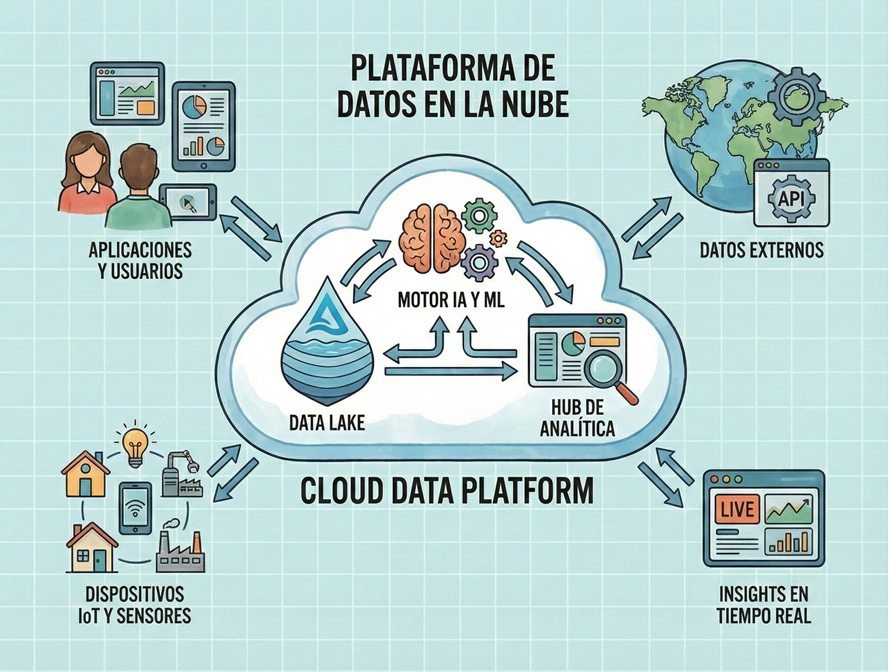
El Ecosistema Cloud Moderno: AWS, Azure y Databricks
La elección de la plataforma define la agilidad de la estrategia de datos. En 2025/2026, el mercado ofrece soluciones integrales que minimizan la gestión de infraestructura.
Amazon Web Services (AWS)
AWS destaca por su madurez y profundidad. AWS Glue proporciona un servicio de ETL serverless potente que incluye catálogos de datos automáticos. Para el almacenamiento analítico, Amazon Redshift ofrece un rendimiento de escala petabyte, mientras que Amazon S3 actúa como el fundamento para cualquier Data Lake escalable.
Microsoft Azure y Fabric
Azure ha evolucionado hacia la unificación con Microsoft Fabric, una plataforma que combina Data Factory, Synapse y Power BI bajo una experiencia «SaaS». Su concepto de OneLake permite virtualizar datos de múltiples nubes, reduciendo drásticamente la duplicidad de información y facilitando la gobernanza centralizada a través de Microsoft Purview.
Databricks y la Arquitectura Lakehouse
Databricks es el pionero del Data Lakehouse, una arquitectura que combina la flexibilidad de los lagos de datos con el rendimiento de los almacenes tradicionales. Con herramientas como Delta Live Tables (DLT), los ingenieros pueden construir pipelines declarativos que gestionan automáticamente la infraestructura y la calidad de los datos, reduciendo el código complejo necesario para procesos de CDC (Change Data Capture).
Arquitecturas Avanzadas: Formatos de Tabla, Mesh y Fabric
El almacenamiento ha pasado de ser un simple «pantano de datos» a un sistema transaccional fiable gracias a los Formatos de Tabla Abiertos.
- Delta Lake: El estándar de Databricks, optimizado para Spark y con fuerte soporte para transacciones ACID.
- Apache Iceberg: Muy popular por su neutralidad de motor, permitiendo que herramientas de AWS, Azure y Snowflake consulten los mismos archivos sin fricción.
- Apache Hudi: Especializado en «upserts» y borrados rápidos, ideal para flujos de streaming intensivos.
Data Mesh vs. Data Fabric
A nivel organizativo, las empresas enfrentan el reto de la escala. El Data Mesh propone descentralizar la propiedad de los datos hacia los equipos de negocio (Marketing, Finanzas), tratándolos como productos independientes. Por otro lado, el Data Fabric busca utilizar IA y metadatos para «tejer» una capa de integración virtual sobre sistemas aislados, facilitando el descubrimiento automatizado. En 2026, la tendencia es un enfoque híbrido que usa la automatización de Fabric para habilitar la descentralización de Mesh.
Tendencias Disruptivas: Zero-ETL y Tiempo Real
El movimiento Zero-ETL busca eliminar la necesidad de construir tuberías manuales frágiles.
- AWS: Ofrece integraciones directas entre Amazon Aurora y Redshift, replicando transacciones en segundos sin intervención del ingeniero.
- Azure: Permite el «mirroring» de bases de datos como Cosmos DB o Azure SQL directamente en Microsoft Fabric, eliminando la latencia de procesamiento.
Estas tecnologías permiten que las empresas reaccionen al instante ante cambios en el mercado, detecten fraudes financieros en milisegundos o ajusten precios dinámicamente según la demanda.
Ingeniería de Datos para Inteligencia Artificial (GenAI)
La IA generativa ha redefinido las prioridades del ingeniero de datos. Los modelos RAG (Retrieval-Augmented Generation) requieren pipelines especializados que alimenten a los LLMs con datos privados y actualizados.
Un pipeline RAG exitoso implica:
- Ingesta de No Estructurados: Procesar PDFs, audios y documentos internos.
- Fragmentación (Chunking): Dividir el texto en bloques semánticos coherentes.
- Embeddings y Bases Vectoriales: Convertir texto en vectores numéricos y almacenarlos en bases de datos como Pinecone, Weaviate o las capacidades vectoriales de Azure AI Search y AWS Kendra.
El ingeniero debe asegurar que, si un manual corporativo cambia, el vector en la base de datos se actualice casi instantáneamente para evitar «alucinaciones» del modelo de IA.
Casos de Estudio y Aplicaciones Sectoriales
Retail: Inventario e Hiper-personalización
En el comercio minorista, la ingeniería de datos permite mejoras en el margen operativo de hasta un 60%. Al integrar datos de POS, inventarios en tiempo real y comportamiento web, los minoristas pueden enviar ofertas personalizadas justo cuando el cliente está en la tienda.
Salud: Genómica y Medicina de Precisión
La ingeniería de datos está acelerando diagnósticos complejos (como el cáncer) de semanas a horas. El uso de IoT y sensores ponibles permite el monitoreo constante de signos vitales, prediciendo anomalías cardíacas antes de que ocurran.
Finanzas: Detección de Fraude con Grafos
Las instituciones financieras usan bases de datos de grafos (como Neo4j o Amazon Neptune) para identificar redes de fraude que los sistemas tradicionales no detectan. Al analizar las relaciones entre dispositivos, IPs y transacciones en tiempo real, se pueden bloquear ataques complejos en milisegundos.
Conclusiones y Futuro de la Disciplina
Hacia 2026, la ingeniería de datos se encamina hacia la «invisibilidad» técnica mediante la automatización. El uso de Rust en lugar de Python/Java está reduciendo los costos de computación hasta en un 70% debido a su eficiencia de memoria. La IA no solo consumirá datos, sino que actuará como un «copiloto» para generar un gran porcentaje de los nuevos pipelines, permitiendo que el ingeniero se enfoque en la estrategia y la arquitectura de alto valor.
El éxito de una organización dependerá de su capacidad para construir una infraestructura resiliente para servir datos que no solo sean informativos, sino activables en tiempo real.
Para terminar, les dejamos la siguiente pregunta:
En un entorno donde la IA demanda datos frescos y de alta calidad para ser efectiva, ¿Qué tan madura es la capacidad de su organización para transformar datos en acciones inmediatas en un contexto dominado por la IA?
Esperamos sus respuestas en los comentarios.